对于使用系统原生组件开发的桌面应用,可以使用系统提供的方案(WAD、Apple Automator)进行自动化,但是某些例如PC版微信、微信开发者工具不使用原生组件(可能出于开发效率考虑)的应用,就束手无策了。
于是有人提出来一种方案,基于图像识别的模式,不管你使用什么技术实现,我都当成图像处理。代表性方案有:
今天要说的也是类似的方案,不过是基于 pyautogui 和 pytesseract 的。
官方对他的定义如下
A cross-platform GUI automation Python module for human beings. Used to programmatically control the mouse & keyboard.
主要功能有:
其主要解决的问题是鼠标和键盘的自动操作(一个类似按键精灵的东西),通过识别子图片来定位子元素,屏蔽了应用的实现细节。
这种实现思路理论上对任何应用都适用。
pyautogui.moveTo(x, y, duration=0.2)pyautogui.click(x, y)pyautogui.locateCenterOnScreen('piece.png', grayscale=False)
pyautogui只能做一些点点点的操作,对于自动化来讲缺少了核心功能——获取和判断界面的元素,这也是其核心的软肋。
从图片里提取文本是很难的一件事,于是轮到 pytesseract 出场了。

pytesseract 是 Google 项目 Google’s Tesseract-OCR Engine 的封装,使用经过训练后的数据识别各个国家的语言,可以获得令人满意的结果。
pytesseract.image_to_string('input.png', lang='eng').strip()
现在我们需要采集微信开发者工具里的包大小数据,包括本地代码、主包两个维度。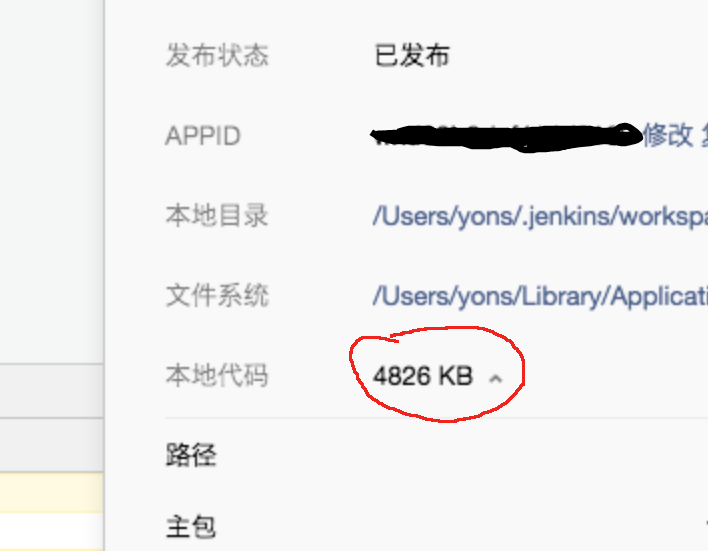
需要做的工作如下:
完成这些工作只需要不到半天时间,由于目标图片较为简单,OCR 识别效果比较理想:
以下为截图的图片:
以下为识别的结果:
4826 KB
对于一些特定的场景,图像识别方案有其合理性,但是应认清该方案的局限性:
在一些特定的场景也许有其价值,例如没有文字或者组件ID但有图片的场景(游戏),或者更极端的Flash等,另外是它可以和现有的测试框架较好的集成(例如BDD、Pytest)等。
黑猫白猫,抓到耗子就是好猫
Copyright © 2015-2022 BY-NC-ND 4.0
